
B2B Lead Scoring: How to Build a Model That Doesn't Break in 90 Days

TLDR
- Most B2B lead scoring models fail within 90 days due to score inflation (new content dilutes signal strength) and signal decay (old behaviors lose predictive value).
- Build a resilient model by layering three components: ICP Tier Weighting to let fit gate the funnel, Behavioral Signal Stacking to prioritize intent over volume, and Negative Scoring to disqualify junk leads.
- For enterprise SaaS, stop scoring individual contacts. Shift to account-based scoring that measures buying committee engagement and coverage, not just one champion's activity.
- A static scoring model is an execution system failure. Success requires treating lead scoring as a continuously calibrated system that adapts to shifting buyer behavior.
- The gap between identifying a high-scoring lead and converting them is an execution problem. The best scoring model is useless if the destination website has conversion friction.
In Q1, your marketing team launches a new B2B lead scoring model. By week two, sales is thrilled. Marketing Qualified Leads (MQLs) are flowing, the MQL-to-SQL handoff friction seems to vanish, and the pipeline dashboard looks green.
By Q2, the model is quietly broken. Leads that score 85+ are converting at the same rate as leads scoring 40. Sales has started ignoring the MQLs because the quality has cratered, but the team doesn't notice for weeks. The dashboard still shows 'MQLs delivered.'
The problem isn't that you built a bad model. It's that you built a static model and placed it inside a dynamic system.
Most teams treat B2B lead scoring as a one-time configuration problem. The teams who actually generate pipeline from it treat it as a continuously calibrated execution system. This guide explains why scoring models degrade, how to build one that survives contact with reality, and why scoring individual contacts is becoming obsolete for any B2B SaaS company selling a high-ACV product.
What B2B Lead Scoring Actually Measures (and What It Doesn't)
B2B lead scoring is a system for ranking prospects by their likelihood to become revenue, using a combination of who they are (fit) and what they do (engagement). It's a mechanism for allocating finite sales attention to the leads with the highest propensity to convert.
Most scoring models break down because they conflate two distinct dimensions:
- Fit Score (Explicit Scoring): This measures how closely a lead matches your Ideal Customer Profile (ICP). It's based on firmographic data (company size, industry, revenue) and demographic data (job title, seniority). Technographic data, like the tools in their current tech stack, also falls here.
- Engagement Score (Implicit Scoring): This measures purchase intent based on behavioral signals. It tracks actions like pricing page visits, demo requests, and content downloads.
A VP of Engineering at a 200-person SaaS company who visited your pricing page once has a high fit score and moderate engagement. A marketing intern at a 10,000-person enterprise who downloaded five ebooks has a low fit score and high engagement. In many simplistic models, they end up with the same composite score but represent completely different pipeline value.
Scoring measures propensity, not certainty. The gap between those two is where most models fail.
Why Most B2B Lead Scoring Models Break Within 90 Days
Lead scoring models are designed as static rule sets but operate inside dynamic systems. Buyer behavior shifts, content libraries grow, and new channels emerge. The model's assumptions silently become outdated. This isn't a bug; it's a feature of any system that isn't actively maintained.
Despite heavy investment in marketing automation, average B2B website conversion rates remain stuck around 2-3%. The issue isn't a lack of tools to score leads; it's the lack of a system to maintain the accuracy of those scores. Two specific failure modes are responsible for this model drift.
Score Inflation: When Every Lead Looks Like a Winner
Score inflation happens when new marketing activities are added without re-weighting existing signals. As you launch a new webinar series, a podcast, and a resource library, more scoring opportunities accumulate. Leads begin earning points faster without any change in their actual purchase intent.
Imagine your team adds a monthly webinar, and every registrant gets +15 points. Within six weeks, 40% of your MQLs are webinar-only leads with no real product intent. The MQL threshold that once filtered the top 15% of leads now passes 35%. Sales stops trusting the scores because the signal has been diluted by noise.
The fix isn't just raising the MQL threshold. It's re-calibrating the entire model against recent conversion data and implementing an "engagement half-life"—the principle that a scoring event's predictive value decays over time.
Signal Decay: When Yesterday's Buying Signal Means Nothing Today
Signal decay is the temporal dimension of model drift. A lead who visited your pricing page 90 days ago and hasn't returned is not the same as one who visited yesterday. Most static models treat them identically.
This is how models accumulate "zombie MQLs"—leads that crossed the threshold months ago based on signals that are no longer predictive. Without time-based decay rules, the MQL queue fills with stale leads, sales loses trust, and the feedback loop between marketing and sales breaks down completely.
A lead's score should depreciate over time. This isn't an edge case; it's a structural requirement for pipeline hygiene that most implementations skip. A scoring cliff, where a score resets after a period of inactivity, is a crude but effective way to handle this. A more nuanced approach involves weekly or monthly score degradation.
How to Build a B2B Lead Scoring Model That Self-Corrects
A resilient scoring model isn't built by assigning more points to more attributes. It's built by structuring three layers that work together: who the lead is (fit), what they've done (behavioral signals), and what disqualifies them (negative scoring).
The order is critical. Fit should gate engagement scoring, not the other way around. A lead who doesn't match your Ideal Customer Profile should never reach the MQL threshold, regardless of their engagement volume. This architecture shifts the focus from accumulating points to qualifying leads through successive filters.
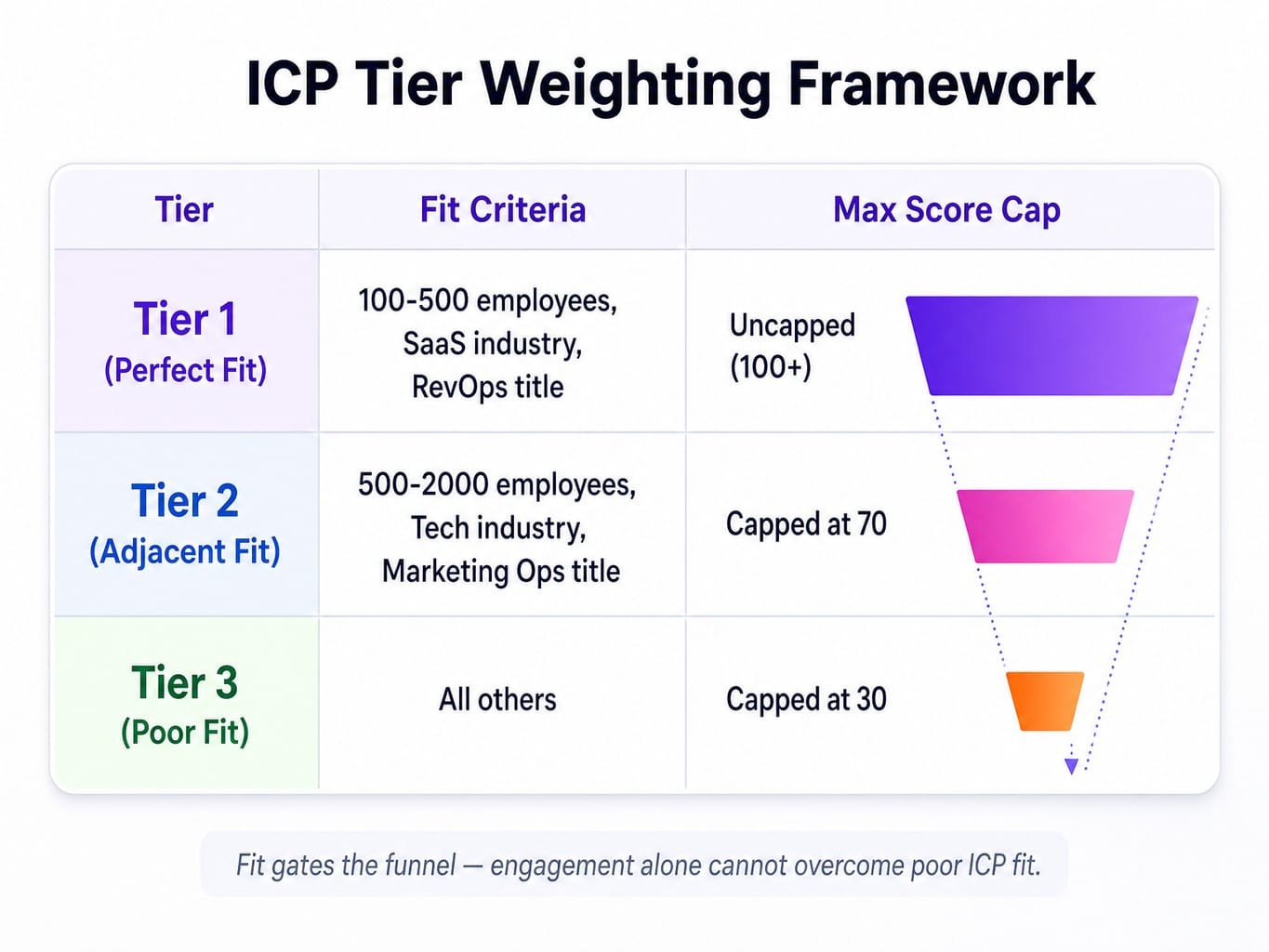
ICP Tier Weighting: Let Fit Gate the Funnel
The first layer of any robust B2B lead scoring model should be firmographic and demographic fit, based on your buyer persona mapping. But fit shouldn't be a binary yes/no. It should be tiered.
ICP tier weighting is a framework where you cap the maximum achievable score based on how closely a lead matches your ideal customer. For a B2B SaaS company selling to mid-market RevOps teams, it might look like this:
- Tier 1 (Perfect Fit): 100-500 employees, SaaS industry, RevOps title. Max Score: 100+
- Tier 2 (Adjacent Fit): 500-2000 employees, tech industry, Marketing Ops title. Max Score: Capped at 70.
- Tier 3 (Poor Fit): All others. Max Score: Capped at 30.
This structure prevents a marketing intern at a Fortune 500 from outscoring the VP at your ideal customer. It ensures that sales capacity is reserved for leads who can actually buy. When thinking about b2b saas executive lead scoring criteria, a Director of Revenue Operations should enter the model with a higher potential score ceiling than a Sales Development Rep at the same company.
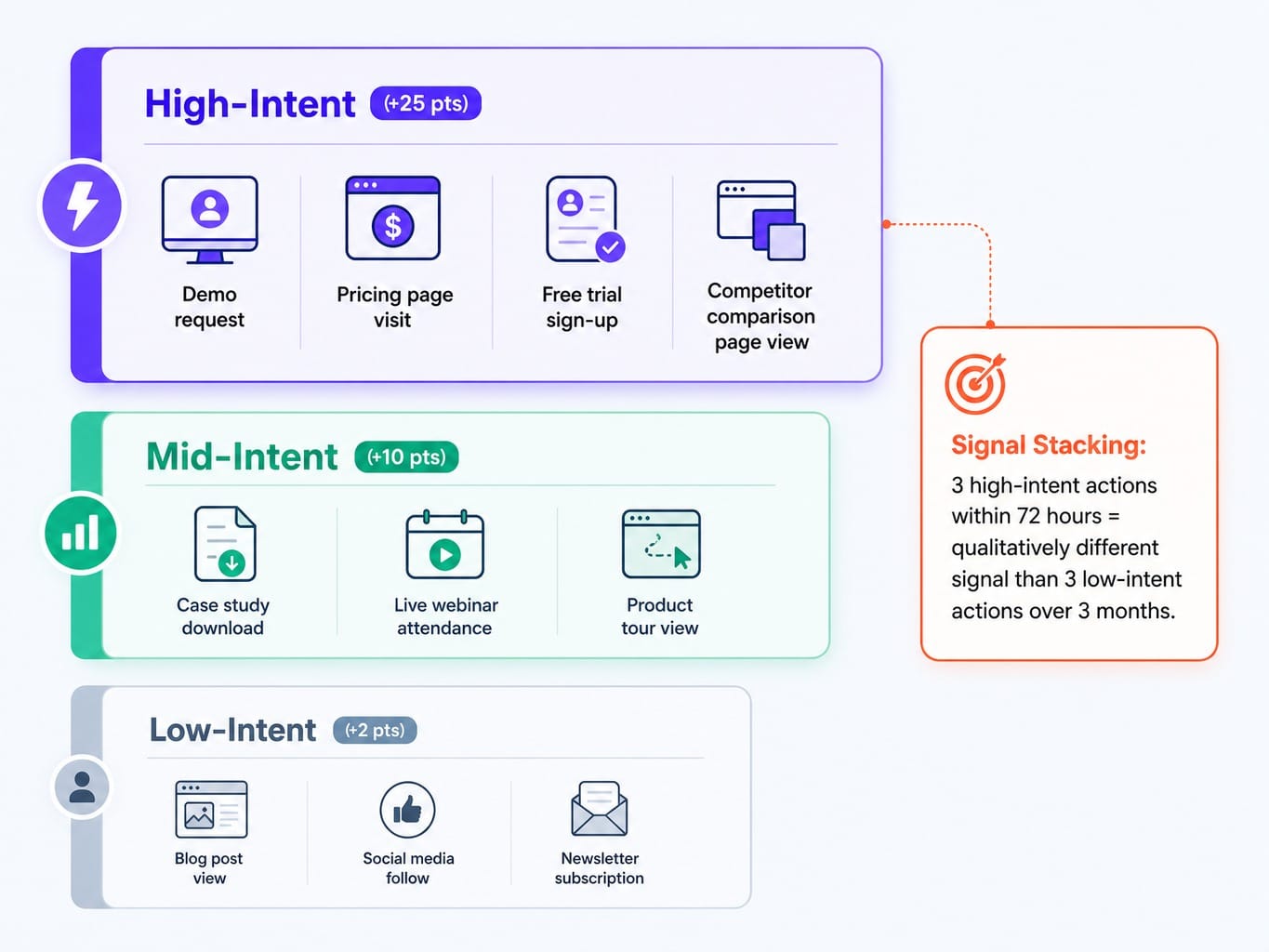
Behavioral Signal Stacking: Weight by Intent, Not Volume
The second layer, behavioral scoring, must weigh signals by purchase intent strength, not just engagement volume. A high volume of low-intent actions is just noise.
Signal stacking is the concept of looking for clusters of high-intent behavior within a short time frame. A pricing page visit, a case study download, and a partial demo request form completion within 72 hours is a fundamentally different signal than three blog visits over three months—even if the raw point totals are the same.
Create a clear hierarchy for behavioral signals:
- High-Intent (e.g., +25 points): Demo request, pricing page visit, free trial sign-up, viewing a competitor comparison page.
- Mid-Intent (e.g., +10 points): Case study download, webinar attendance (live), product tour view.
- Low-Intent (e.g., +2 points): Blog post view, social media follow, newsletter subscription.
This is also where you can incorporate signals from the "dark funnel." Third-party intent data from platforms like Bombora or 6sense can surface off-site buying signals, acting as a score multiplier for accounts already showing ICP fit.
Read more: Bombora Alternatives 2026: 6 Intent Data Providers Evaluated by Signal Quality, Not Feature Lists
Negative Scoring: The Disqualification Layer Most Teams Skip
Negative scoring isn't optional—it's the mechanism that prevents junk lead suppression from failing and protects sales capacity. It's the system running in reverse, actively disqualifying leads that show anti-buying signals.
A functional negative scoring layer should include rules like:
- -100 points: Email domain from a known competitor.
- -50 points: Student or academic email domain (.edu).
- -30 points: Visited the careers or jobs page.
- -20 points: Unsubscribed from a marketing nurture sequence.
- -5 points: Per week of total inactivity after 60 days.
This last point is how score decay becomes operational. It's not a separate system; it's an integrated part of the scoring logic. By implementing negative scoring, you ensure your model is not just identifying good leads but actively filtering out the bad ones, keeping the MQL queue clean and trustworthy. This logic can be built directly into most marketing automation platforms, from HubSpot to Marketo Engage.
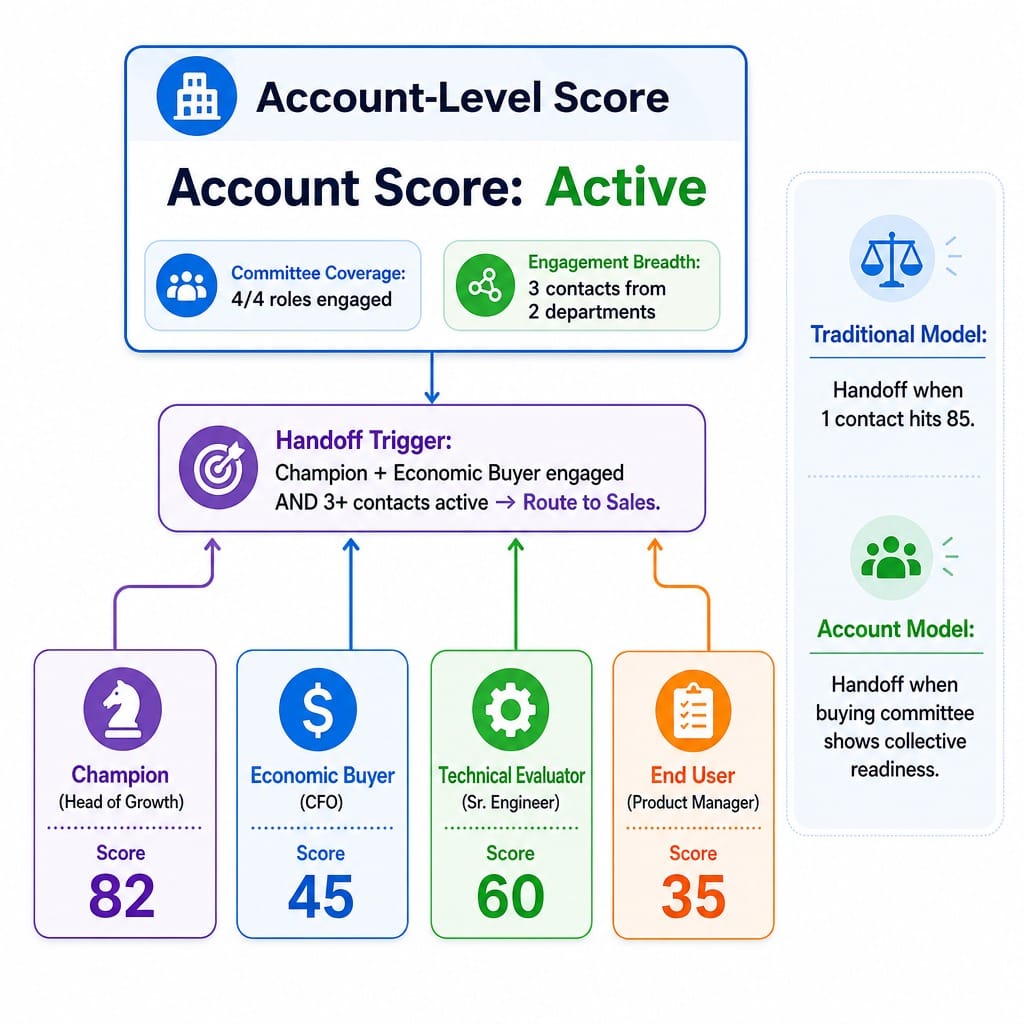
Scoring Buying Committees, Not Individual Contacts
In enterprise B2B SaaS, no individual buys anything. Deals close when a buying committee—a champion, an economic buyer, a technical evaluator, and an end-user—collectively reaches a decision threshold. Yet, most lead scoring models score individual contacts in isolation.
A champion who scores 90 means nothing if the economic buyer has zero engagement. This is why traditional MQLs often fail in complex sales cycles.
The solution is to shift from contact-level scoring to account-based scoring. This involves two key concepts:
- Contact-to-Account Roll-up: Individual contact scores are aggregated into a single account-level score. This score reflects the total engagement from an organization, preventing you from missing a deal just because the activity is spread across multiple people.
- Multi-threaded Account Scoring: An account with three engaged contacts across two departments is a much stronger signal than an account with one hyper-engaged contact. The model should reward engagement breadth, indicating that multiple stakeholders are involved.
For a $50K ACV SaaS product, the handoff to sales shouldn't trigger when one champion hits a score of 85. It should trigger when the account shows engagement from both a champion (e.g., Head of Growth) and an economic buyer (e.g., CFO), or when at least three contacts from the target department are active. This is a more realistic measure of an account's readiness for a sales conversation.
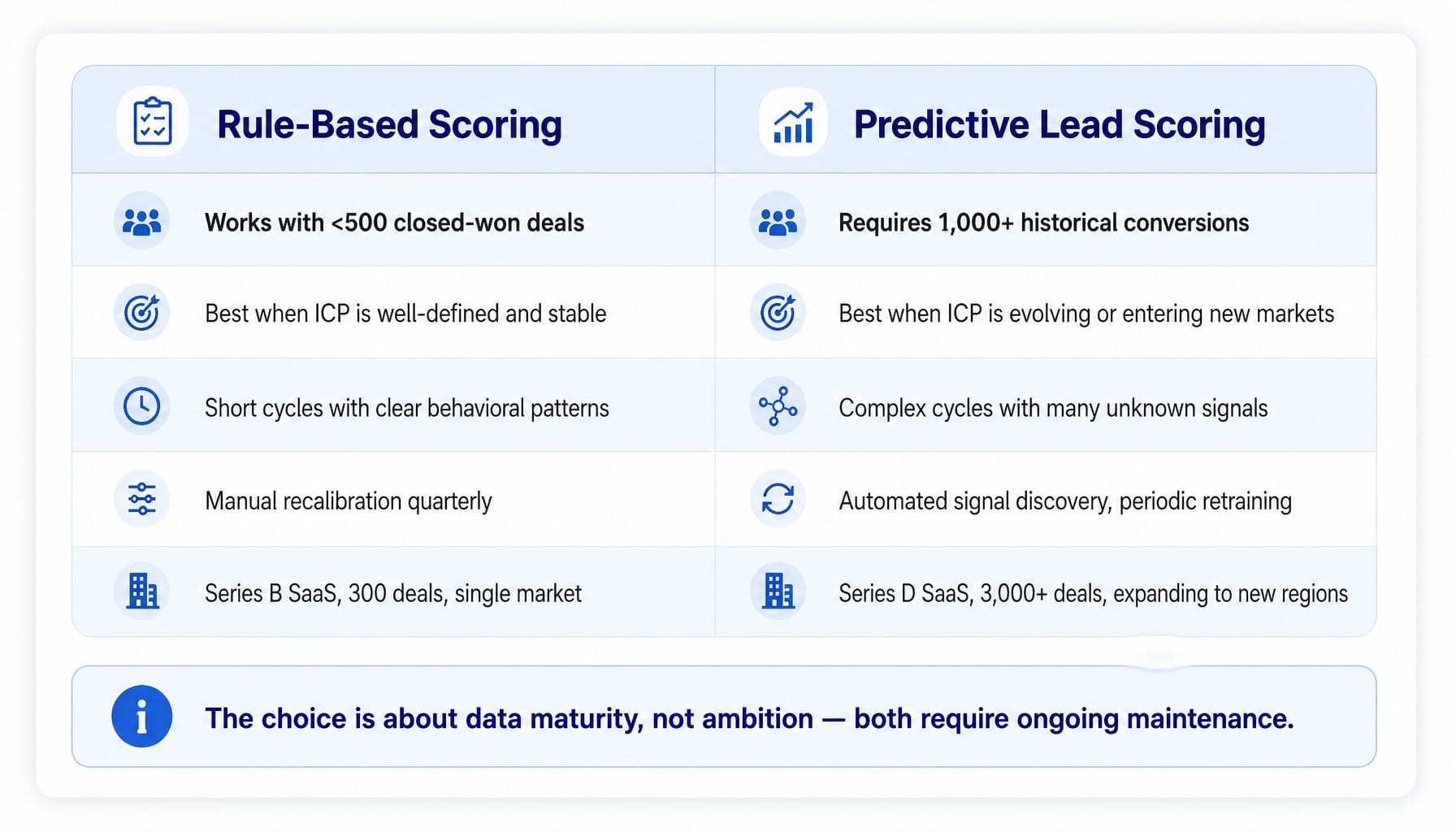
Predictive Lead Scoring vs. Rule-Based Scoring: When Each Makes Sense
The hype around predictive lead scoring often positions it as the only modern solution. But the reality is more nuanced. Predictive models, which use machine learning to identify conversion patterns in historical data, are powerful but require a specific data foundation to work.
Rule-based scoring (the manual system described above) is the right choice when:
- You have fewer than 500-1,000 closed-won deals for a model to train on.
- Your ICP is well-defined and stable.
- Your sales cycle is short and behavioral patterns are clear.
Predictive lead scoring (using tools like HubSpot's predictive scoring, Salesforce Einstein, or Madkudu) becomes necessary when:
- You have 1,000+ historical conversions, providing a rich dataset for the algorithm.
- Your ICP is evolving or you're entering new markets with unknown signals.
- The manual effort of maintaining your rule-based model exceeds a few hours per month.
A Series B SaaS company with 300 historical deals likely won't get better results from a predictive model than from a well-maintained rule-based one. But for a Series D company with 3,000+ deals expanding into a new region, a rule-based model can't adapt fast enough. Even predictive models require a "propensity model retraining cadence," but they automate the signal discovery that becomes a bottleneck at scale.
Read more: 5 Best Predictive Conversion Optimization Tools for Pipeline Revenue in 2026
When Your Scoring Model Needs a System Behind It, Not More Spreadsheets
This entire article has built a specific tension: B2B lead scoring isn't a configuration problem—it's a continuous optimization problem. Models degrade. Buying committees require cross-channel signal aggregation. Predictive models need retraining. All of this demands ongoing execution bandwidth that lean marketing teams simply do not have.
This is the execution gap. Your scoring model identifies who should convert, but what happens when they land on a website with unclear messaging, a broken form, or a confusing user path? The best scoring model in the world can't fix conversion friction at the destination.
This is where an execution system becomes critical. Spike AI operates as the autonomous layer that detects these friction points across your website, SEO, and landing pages, then deploys fixes weekly. It closes the gap between identifying a high-value lead and giving them an experience that actually converts.
Your scoring model prioritizes the who. Spike AI optimizes the what and where. It's the missing system that ensures the traffic your scoring model works so hard to identify doesn't go to waste.
See how Spike AI closes the gap between lead scoring and conversion — book a discovery call.
From Static Points to a Dynamic System
The single most important shift is this: B2B lead scoring is not a setup task. It's an execution system that demands continuous recalibration. The teams who generate real pipeline from it treat it as a living system, not a static project.
Static models will always degrade because buyer behavior is dynamic. Resilient models are built in layers: fit gating the funnel, weighting behavioral signals by intent, and aggressively disqualifying junk leads with negative scoring. For any meaningful deal size, you must score the buying committee, not the contact. And the choice between rule-based and predictive scoring is a pragmatic decision based on data maturity, not ambition.
The next evolution isn't about finding better scoring rules. It's about closing the execution gap between scoring a lead and converting them. The teams that win will be those who treat scoring and conversion as a single, unified system, not two separate workflows.
Frequently Asked Questions
How often should you recalibrate a B2B lead scoring model?
Review MQL-to-SQL conversion rates monthly and perform a full recalibration against closed-won/lost data quarterly. If your MQL-to-opportunity conversion rate shifts more than 10% in either direction, recalibrate immediately. The goal is to catch model drift before sales loses trust in the scores.
Should product usage data factor into B2B SaaS lead scoring?
Yes. For PLG-native companies, product telemetry (feature activation, workspace invites) is the strongest intent signal. Tools like Pocus and Koala surface these Product Qualified Leads (PQLs). Weight product usage signals higher than marketing engagement, as they demonstrate evaluated intent, not just passive content consumption.
What lead scoring thresholds work for enterprise SaaS sales cycles?
There is no universal threshold. A useful heuristic: set your MQL threshold so that sales can follow up on every MQL within 24 hours. If they can't, it's too low. For long enterprise cycles, consider replacing binary MQL/SQL thresholds with continuous probability scores that trigger different actions at different confidence levels.
How do you prevent score inflation when leads engage with non-buying content?
Cap the maximum points achievable from top-of-funnel content (blogs, podcasts) at 20-30% of the MQL threshold. A lead should never reach MQL on content consumption alone. Also, categorize content by funnel stage and assign points accordingly—a pricing page visit should always be worth more than a blog view.
What role does third-party intent data play in modern B2B lead scoring?
Third-party intent data from providers like Bombora or 6sense surfaces buying signals happening outside your owned channels (e.g., competitor research). Use it as a score multiplier for accounts that already show strong ICP fit, not as a standalone scoring input. Intent data without fit context produces false positives.
How do you score executive-level contacts differently from individual contributors?
Executive contacts (VP+, C-suite) should receive a demographic score multiplier (typically 1.5-2x) because their engagement carries more deal influence. However, a single executive visit is often just research. Combine executive scoring with buying committee coverage metrics to avoid false positives from isolated, high-level touches.



